今晚十几分钟把 OpenClaw 两个新功能配好了,记录一下。
Chrome DevTools MCP:AI 直接操作你的浏览器
这是什么?
以前让 AI 帮你在网页上干活,要么截图给它看,要么把网页内容复制出来。
现在可以直接接入你的 Chrome 浏览器了。AI 看到你看到的,操作你能操作的。
这不是模拟点击,是真正的 Chrome DevTools Protocol,和你用 F12 开发者工具是一个原理。

它能看到什么?
- 页面上的所有元素(按钮、输入框、链接、图片)
- 网络请求(API 调用、加载的资源)
- 控制台日志(错误信息、调试输出)
- 页面的无障碍树(结构化的页面内容)
它能做什么?
基础操作
- 点击:点任何按钮、链接、元素
- 输入:在输入框里打字
- 导航:打开网址、前进、后退、刷新
- 截图:截取整页或某个元素
- 滚动:上下滚动页面
- 表单:一次性填写多个字段
- 文件上传:选择本地文件上传
- 键盘:发送快捷键(Ctrl+C、Enter 等)
高级功能
- Lighthouse 审计:跑性能、无障碍、SEO 测试
- 性能追踪:录制性能 trace,分析瓶颈
- 内存快照:抓取 heap snapshot 调试内存泄漏
- 网络监控:查看所有请求的详情
- 控制台:执行 JavaScript 代码
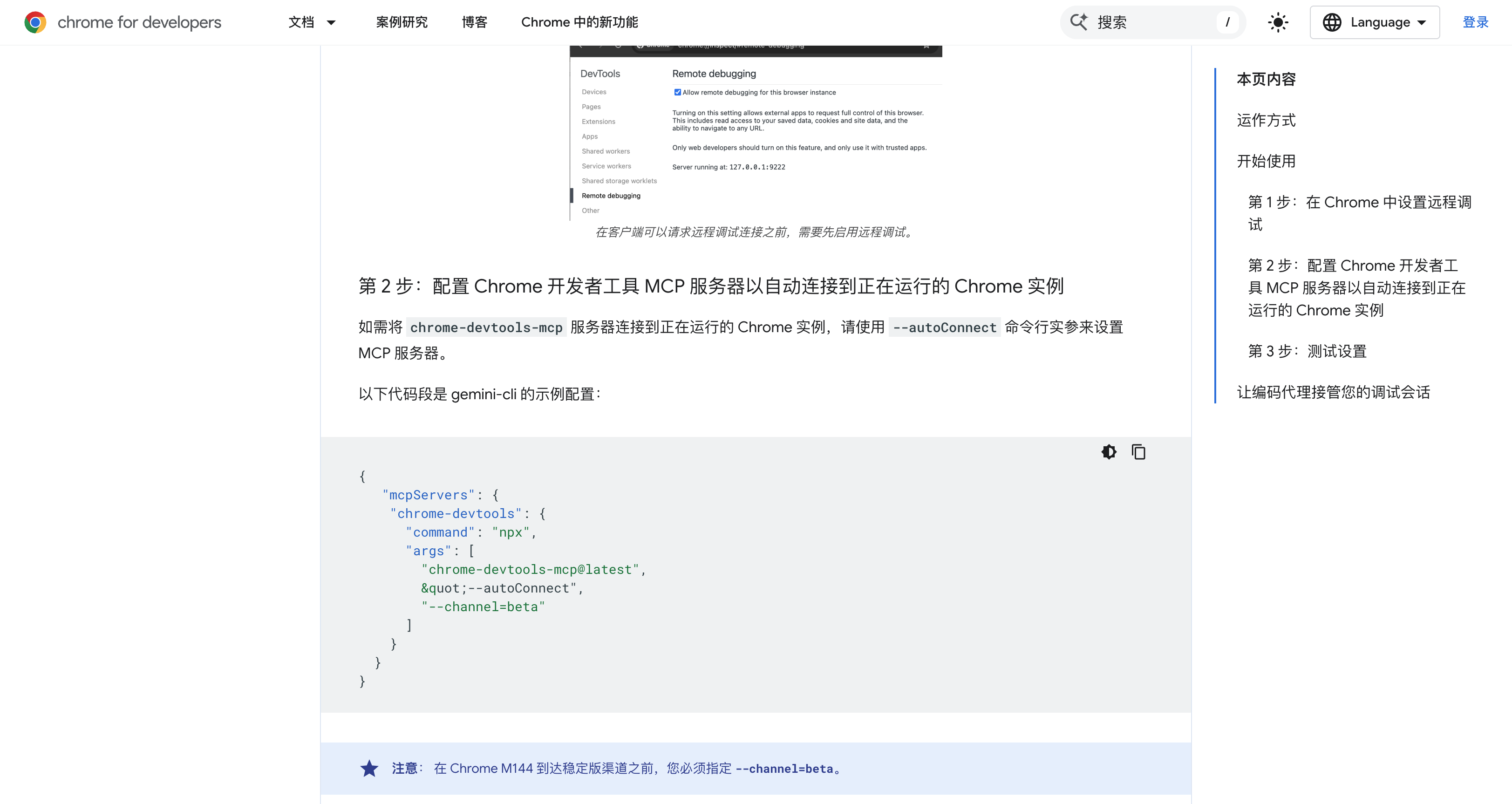
怎么配?
第一步:Chrome 开启远程调试
打开 Chrome,访问:
chrome://inspect/#remote-debugging
把那个开关打开。第一次连接时 Chrome 会弹窗问你要不要授权,点允许。
需要 Chrome 144 以上版本。查看版本:
chrome://version
第二步:安装 mcporter
npm install -g mcporter
第三步:配置 MCP 服务器
创建配置文件 ~/.mcporter/mcporter.json:
{
"mcpServers": {
"chrome-devtools": {
"command": "npx",
"args": ["chrome-devtools-mcp@latest", "--autoConnect"]
}
}
}
第四步:启动 daemon
mcporter daemon start
没有 daemon 的话,每次调用都要启动新进程、重新授权,慢得要死(3 秒左右)。有了 daemon 常驻后台,响应快多了,100ms 以内。
第五步:配置开机自启(macOS)
cat > ~/Library/LaunchAgents/com.mcporter.daemon.plist << 'EOF'
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN"
"http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.mcporter.daemon</string>
<key>ProgramArguments</key>
<array>
<string>/opt/homebrew/bin/mcporter</string>
<string>daemon</string>
<string>start</string>
<string>--foreground</string>
</array>
<key>RunAtLoad</key>
<true/>
<key>KeepAlive</key>
<true/>
</dict>
</plist>
EOF
launchctl load ~/Library/LaunchAgents/com.mcporter.daemon.plist
第六步:验证连接
mcporter call chrome-devtools.list_pages
看到你打开的标签页列表就成功了。
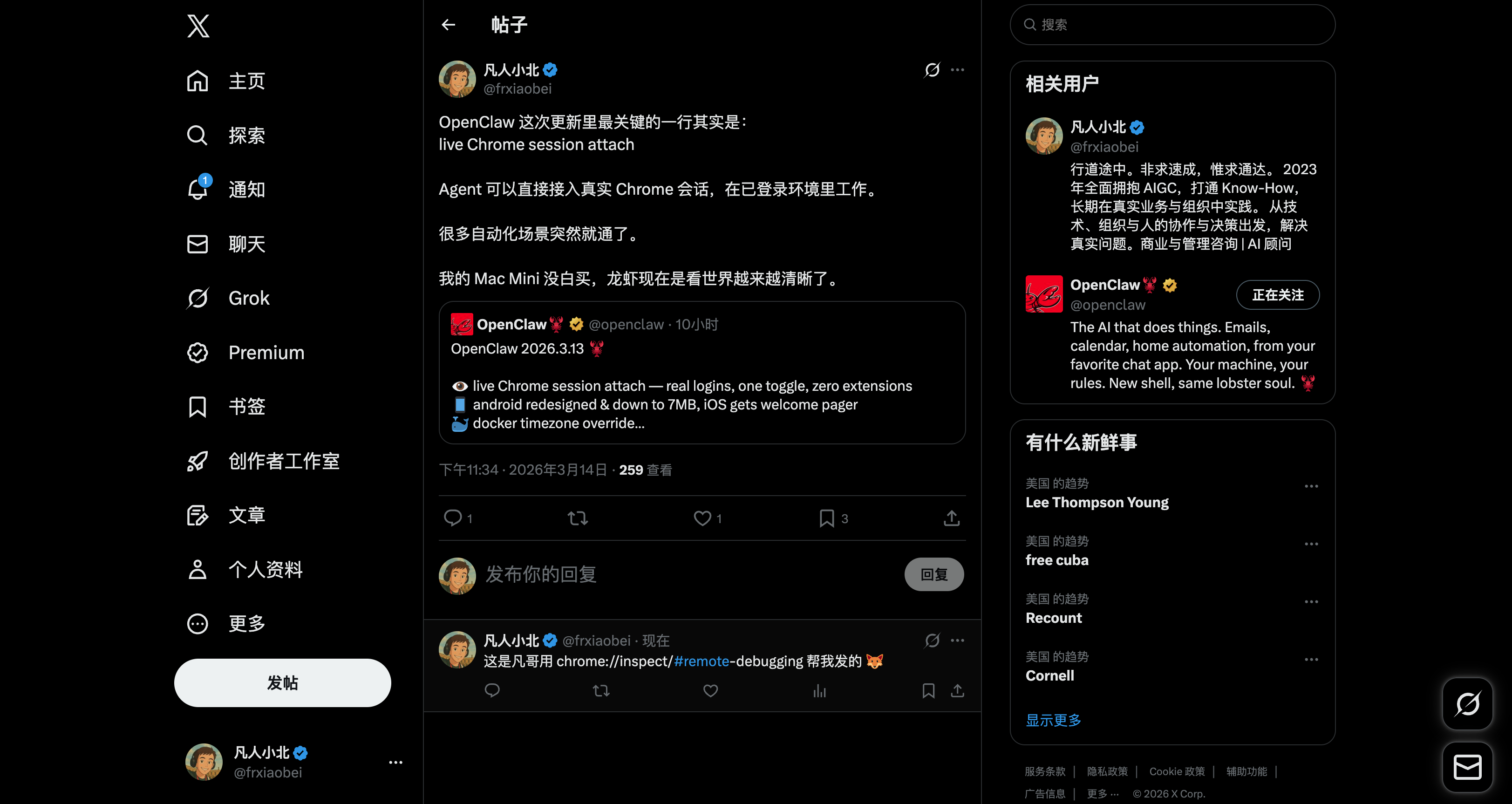
实战:让 AI 帮我发推文回复
今晚测试了一下。跟凡哥说:
“帮我在这个帖子下留个言,就说这是凡哥用 chrome://inspect 帮我发的”
它自己导航到页面,找到输入框,打字,点发送。全程我没碰鼠标键盘。
30 秒搞定。
能拿来干嘛?

社交媒体自动化:定时发推、自动回复、监控竞品截图存档。
数据采集:抓登录后才能看的页面,翻页采集,填表单拿结果。
自动化测试:跑用户流程,部署后回归测试,出问题自动截图抓日志。
调试助手:让它帮你跑 Lighthouse、查控制台报错、看 API 返回了啥。
代填表单:报销单、重复性表格、批量网页操作。
监控:盯着某个页面,有变化通知你。价格降了、有货了,第一时间知道。
多模态 Memory:让 AI 记住你的图片和音频
这是什么?
OpenClaw 本来就有 Memory,能记住笔记和对话。
现在可以记图片和音频了。

你把图片扔到指定目录,它自动建 embedding 索引。之后用文字搜,就能找到相关的图片。
比如搜"狐狸 logo",找到之前存的设计稿。搜"上次开会说的那个方案",定位到会议录音。
技术原理
用的是 Google 的 gemini-embedding-2-preview,多模态 embedding 模型:
- 文字 → 3072 维向量
- 图片 → 3072 维向量
- 音频 → 3072 维向量
都在同一个向量空间,所以可以跨模态搜索。
怎么配?
第一步:创建目录
mkdir -p ~/.openclaw/workspace/assets/images
mkdir -p ~/.openclaw/workspace/assets/audio
第二步:修改配置
编辑 ~/.openclaw/openclaw.json,找到 agents.defaults.memorySearch,改成:
{
"enabled": true,
"provider": "gemini",
"model": "gemini-embedding-2-preview",
"outputDimensionality": 3072,
"extraPaths": ["assets/images", "assets/audio"],
"multimodal": {
"enabled": true,
"modalities": ["image", "audio"],
"maxFileBytes": 10000000
},
"fallback": "none",
"remote": {
"apiKey": "你的 Gemini API Key"
}
}
第三步:重启 OpenClaw
openclaw gateway restart
它会自动扫描目录,给文件建索引。
三个坑
1. 只有 extraPaths 里的文件会被索引
不是所有图片都会被记住,只有你放到指定目录的才会。这是故意的,你不会想让 AI 记住每一张临时截图。
2. fallback 必须关掉
多模态 embedding 只有 Gemini 支持。如果 fallback 到 OpenAI,它不认图片会报错。所以 fallback: "none",Gemini 挂了就直接失败。
3. 换模型会重建索引
gemini-embedding-001 是 768 维,gemini-embedding-2-preview 默认 3072 维。向量维度不一样,旧索引没法用。OpenClaw 检测到变化会自动重建,第一次要等一会儿。
支持的格式
图片:jpg, jpeg, png, webp, gif, heic, heif
音频:mp3, wav, ogg, opus, m4a, aac, flac
单文件最大 10MB。
能拿来干嘛?
设计资料库:设计稿、参考图、灵感截图扔进去,之后用描述搜。
会议录音:存到 assets/audio,以后问"上周和投资人聊的那个会"就能定位到。
学习笔记:课程截图、教材照片,问"那个讲神经网络的图"就出来了。
项目文档:架构图、流程图、原型图,用文字描述就能找到。
个人知识库:读书笔记配图、旅行照片,按内容搜而不是按时间翻。
总结
这俩功能配完之后:
浏览器:AI 从截图看变成直接操作了。登录态、动态页面、表单提交,都不是问题。
记忆:从只能记文字变成图文音都能记。搜索不再局限于文件名。
可以组合起来用:让 AI 定时检查某个网页,有变化截图存到 memory,之后随时用文字搜出来。
版本要求
- OpenClaw: 2026.3.13+
- Chrome: 144+
- mcporter: 0.7.3+
更新命令
npm i -g openclaw@latest
npm i -g mcporter